
Kaffee zubereiten mit MAX78000 und einer Prise KI
über
Moderne Hardware kann den Einsatz von Convolutional Neural Networks (CNNs) beschleunigen, die oft zur Analyse von Bildern oder Audiodaten eingesetzt werden. Eine damit ausgestattete Anwendung bekommt so die neue Möglichkeit, Umweltdaten zu verarbeiten und mit ihrer Umgebung zu interagieren. Die für ein CNN erforderliche Rechenleistung fordert eine einzelne CPU sehr und kann sie stark ausbremsen. Daher wird hier ein spezieller Beschleuniger eingesetzt. Bei Ihrem PC kann dies mit Hilfe Ihrer Grafikkarte oder spezielle Beschleuniger wie den Tesla-Karten von NVIDIA erfolgen (oder diese Beschleuniger sind im System selbst eingebaut, wie bei Apples neuem M1-Prozessor). Die MCU MAX78000 von Maxim beherbergt neben einer Cortex-M4F-MCU und einem RISC-V-Kern auch noch einen CNN-Beschleuniger (siehe Datenblatt). Dies ermöglicht eine Low-Power-CNN-Verarbeitung und eröffnet neue Wege zur Integration von KI in embedded Designs.

Meine Kollegen bei Elektor haben die Hardware schon in zwei Artikeln beschrieben [2] [3], daher werde ich mich in diesem Beitrag auf die Software rund um den MAX78000 konzentrieren. Außerdem wird ein CNN trainiert, um einige Schlüsselwörter zu erkennen und einige Hardware-Interaktionen durchzuführen. Das verwendete Board MAX78000FTHR (Bild 1) ist auch im Elektor Store erhältlich.
Für einen ersten Test habe ich das Beispiel der Schlüsselwort-Erkennung modifiziert, um eine sprachgesteuerte Kaffeemaschine zu realisieren. Da wir überall auf dem Globus immer noch mit dem Corona-Virus zu kämpfen haben, geht von gemeinsam genutzten Geräten im Büro wie einer Kaffeemaschine nach wie vor das reale Risiko der Verteilung von Viren aus. Eine Kaffeemaschine, die sich bedienen lässt, ohne dass man eine Taste etc. berühren muss, eignet sich prima als Demonstrationsobjekt für eine Software-Lösung mit dem MAX78000. Das mitgelieferte SDK erlaubt die Programmierung in C oder C++. Die Dokumentation ist im Maxim GitHub Repository für den MAX78000 zu finden.
Zwei Seiten der gleichen Medaille
KI auf embedded Geräten zu betreiben, erfordert – je nach Vorwissen - eine Reihe neuer Fähigkeiten. Auch wer schon mit neuronalen Netzwerken zu tun hatte, wird für gewöhnlich Probleme habe, dieses Thema auf die Welt der embedded Entwicklung zu übertragen. Doch auch gestandene embedded Entwickler sind wird sich beim Thema KI eher schwer tun. Wenn man sich entscheidet, vortrainierte Netze aus den Samples zu verwenden, wird eine durchschnittliche Entwicklungsmaschine ausreichen.
In diesem Beitrag versuche ich, beiden Lagern gerecht zu werden und beginne mit dem Training eines neuronalen Netzwerks. Um die Sache zu vereinfachen, wird ein bestehendes Beispiel modifiziert, anstatt bei null anzufangen. Auch dieses Vorgehen vermittelt einen Eindruck von den verwendeten Tools.
Die Embedded-Entwicklung und damit die Implementierung in den MAX78000 selbst wird ein zweiter Schritt sein. Wenn Sie bisher nur wenig mit dem embedded Bereich in Kontakt gekommen sich, wird das eine Herausforderung für Sie werden. Daher werden die wichtigsten Konzepte in zwei statt nur einem Artikel behandelt. Diese erste Folge konzentriert sich auf KI. Erst im zweiten Beitrag geht es verstärkt um die Entwicklung mit dem MAX78000.
CUDA-fähige GPUs empfohlen
Wer sich mit neuronalen Netzen und deren Erstellung beschäftigen möchte, der sollte insbesondere diesen Aspekt beachten: Um neuronale Netze für den MAX78000 zu trainieren, sollte eine CUDA-fähige GPU von NVIDIA im dafür eingesetzten PC stecken. Da AMD- und Intel-GPUs keine Unterstützung für Trainings-Frameworks für tiefe neuronale Netze wie Tensor Flow und PyTorch bieten, bleiben nur CUDA-GPUs von NVIDIA. Doch selbst wenn Sie eine CUDA-fähige GPU verwenden, muss es sich dabei mindestens um einen Chip der Maxwell-Generation (GTX 9) oder Tesla (K80) handeln.
Anfang 2021 zum Zeitpunkt der Arbeit an diesem Artikel sind neue GPUs sehr kostspielig geworden. Das muss man wissen, wenn man extra hierfür die Grafik aufrüsten möchte. Sie können natürlich auch einfach die „normale“ CPU für alle Berechnungen der neuronalen Netze verwenden, aber das erhöht die benötigte Zeit um mindestens den Faktor 10!
Intelligente Kaffeemaschine mit MAX78000
Eine Kaffeemaschine zu modifizieren ist etwas, das sich die meisten von uns aus den unterschiedlichsten Gründen durchaus vorstellen können. Vielleicht wollen Sie WLAN nachrüsten oder eine persönliche Aufbrüh-Funktion. Oder vielleicht haben Sie eine defekte Maschine repariert und wollen gleich einige Verbesserungen hinzufügen? Mein Proof of Concept ist bei weitem nicht perfekt. Es soll die folgenden Funktionen bieten:
- Die Maschine soll „Happy“ als ihren Namen erkennen.
- Sie soll fragen, ob sie einen Kaffee brühen soll.
- Sie soll fragen, ob eine Tasse eingestellt ist.
- Benutzerrückmeldung über LCD.
Die Hardware ist recht einfach. Benötigt wird:
- MAX78000FTHR RevA Platine (Bild 1)
- Lochrasterplatine
- Jumper-Draht
- 2,2"-LCD aus dem Elektor Store (Bild 2)

Training und Synthese
Maxim stellt einige Beispiele zur Verfügung, um die in verwendeten Convolutional Neural Networks zu trainieren. Eine Anleitung für die benötigte Software finden Sie auf Maxims GitHub-Seite. Die Beispiele laufen unter Linux erfolgt und man sollte (wie schon erwähnt) eine CUDA-fähige Grafikkarte haben. Zu Ihrer Information: Mit einer GeForce GTX 1050Ti von NVIDIA hat das Training für die kws20_demo auf einem PC mit der CPU Ryzen 2700X von AMD mit CUDA-Beschleunigung etwa 3,5 h gedauert.Es gibt einige experimentelle Treiber, die es erlauben, das Windows Subsystem für Linux zu verwenden, um auf die CUDA-Beschleunigung zuzugreifen. Im Sinne der Stabilität wird aber empfohlen, auf eine Debian-Linux-Variante wie Ubuntu zu setzen. Daher wird in dieser Folge beschrieben, wie man mit einer frischen Installation von Ubuntu 20.04 und den von Maxim bereitgestellten Tools beginnt.
Der erste Schritt nach der Installation besteht darin, die proprietären NVIDIA-Treiber für die CUDA-Beschleunigung zu installieren. Unter Ubuntu verwenden Sie Software and Updates und fügen die Treiber für Ihre Karte unter dem Reiter Additional Drivers hinzu. Die nötigen Treiber für die verwendete GTX1050Ti sehen Sie in Bild 3.
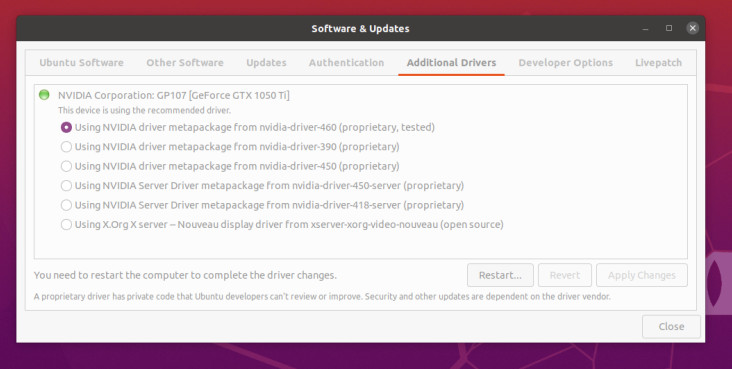
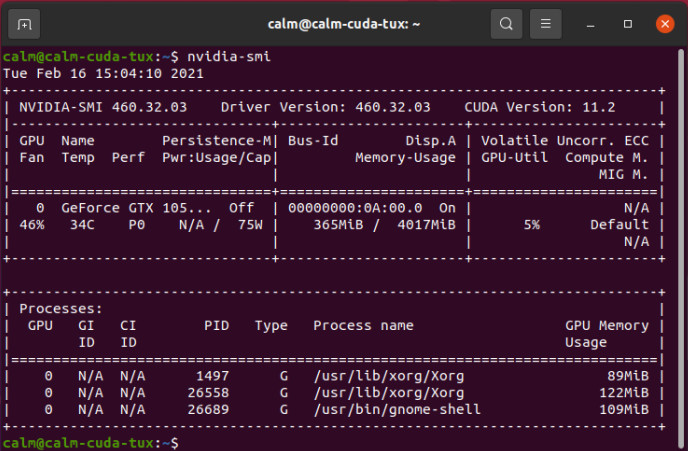
Anschließend folgt ein Neustart des PCs. Wenn danach immer noch eine Displayausgabe vorhanden ist, haben Sie die NVIDIA-Treiber zum Laufen gebracht. Das kann man mit dem Tool nvidia-smi in einem Konsolenfenster überprüfen, wie in Bild 4 zu sehen ist. Hier wird auch die verwendete CUDA-Version (in diesem Fall 11.2) ausgegeben.
echo $PATH | grep -q -s "~/xpack-riscv-none-embed-gcc-10.1.0-1.1/bin"
if [ $? -eq 1 ] ; then
PATH=$PATH:~/xpack-riscv-none-embed-gcc-10.1.0-1.1/bin
export PATH
RISCVGCC_DIR=~/xpack-riscv-none-embed-gcc-10.1.0-1.1/
export RISCVGCC_DIR
fi
Damit können Sie die Netzwerktrainings durchführen. Der zweite erforderliche Teil ist die Synthese. Dieser Schritt wandelt ein trainiertes Netzwerk in etwas um, das ein MAX78000 verwenden kann. Für die Synthese finden Sie hier die Installationsanleitung. Da Sie den Trainingsteil bereits installiert haben, überspringen Sie den Abschnitt Upstream Code in der Anleitung.Wenn Sie bis hierher dabei waren, können Sie Modelle zu trainieren und synthetisieren, die mit dem MAX78000 verwendet werden können. Sie können also auch Skripte verändern, um neue zu erkennende Elemente zu trainieren, wenn diese in den Trainingsdaten vorhanden sind.
Modifizieren und Trainieren des Keyword-Spotting-Beispiels
Eines der mitgelieferten Beispiele ist das Keyword-Spotting. Wie bereits im Artikel von Clemens Valens erwähnt, hört erkennt Demo 20 vortrainierte Wörter. Diese Wörter sind „up, down, left, right, stop, go, yes, no, on, off, one, two, three, four, five, six, seven, eight, nine, zero“ und werden aus einer Menge von 31 Wörtern ausgewählt, die von einem Benutzer trainiert werden können. Die vollständige Liste der unterstützten Schlüsselwörter ist „backward, bed, bird, cat, dog, down, eight, five, follow, forward, four, go, happy, house, learn, left, marvin, nine, no, off, on, one, right, seven, sheila, six, stop, three, tree, two, up, visual, wow, yes, zero”.Für die Demo bleiben es bei 20 Schlüsselwörtern, aber es werden nun „marvin, happy, backward, forward, stop, go, yes, no, on, off, one, two, three, four, five, six, seven, eight, nine, zero” verwendet.
Zur Änderung der bisherigen Liste navigiert man zum Ordner ai8x-training auf dem installierten Ubuntu-Rechner (siehe Bild 5).
An diesem Punkt würde das Training beginnen und je nach Hardware einige Stunden oder Tage in Anspruch nehmen. Nach Ende des Trainings enthält ein neuer mit Datum versehender Ordner ./logs/ die Trainingsergebnisse. Diese müssen nun synthetisiert werden, damit sie vom MAX78000 verwendet werden können.
Synthese der Daten
Nach Abschluss des Trainings müssen die Daten in eine Form gebracht werden, die der MAX78000 laden kann. Hierzu muss man im Ordner ai8x-synthesis Dateien verschieben und löschen. Um sicherzustellen, dass keine alten Daten verwendet werden, wird der Inhalt des trainierten Ordners gelöscht. Aus dem Ordner ai8x-training/logs/{start time}/ wird die Datei best-pth.tar in den Ordner ai8x-synthesis/trained/ kopiert, da beide Dateien für die weitere Verarbeitung benötigt werden. Nun wird das Terminal gestartet und zum Ordner ai8x-synthesis navigiert.Jetzt wird source bin/activate ausgeführt, um die Python-Umgebung einzurichten. Dann wird eine Quantisierung des kopierten trainierten Modells mit ./quantize.py trained/best.pth.tar trained/ai85-kws20-v3-qat8-q.pth.tar -device MAX78000 -v in eine quantisierte Datei namens ai85-kws20-v3-qat8-q.pth.tar im Ordner trained durchgeführt. Nach der Quantisierung kann man einige Codes und die endgültigen nutzbaren Dateien für den MAX78000 generieren.
Der letzte Schritt ist die Codegenese für die spätere Verwendung. Im noch offenen Terminal gibt man ./ai8xize.py --verbose --log --test-dir ~/MAX78000/ --prefix kws20_v3 --checkpoint-file trained/ai85-kws20_v3-qat8-q. pth.tar --config-file networks/kws20-v3-hwc.yaml --softmax --device MAX78000 --compact-data --mexpress --timer 0 --display-checkpoint --board-name FTHR_RevA ein.
Dadurch wird ein Ordner MAX78000 im Home-Verzeichnis erzeugt, der eine kleine Basisanwendung enthält, die sich selbst gegen vordefinierte Testdaten testet. Diese Anwendung wird innerhalb eines Ordners kws20_v3 liegen, ebenso wie die Dateien weights.h, cnn.h und cnn.c, die das CNN und seine Funktionen enthalten. An diesem Punkt beginnt das embedded Design, da nun ein CNN vorliegen sollte, das auf die modifizierten Schlüsselwörter erkennt.
Weitere Lektüre
Möchten Sie einen weiteren Schritt in die Welt der CNNs machen? Beginnen Sie mit dieser Einführung. Wenn Sie dem Tutorial folgen, werden Sie ein wenig mehr davon verstehen, was Skripte und Trainingsteile tun. Auch NumPy wird Ihnen einige grundlegende Ideen über die Mathematik hinter dem CNN vermitteln und warum man diese verwendet. Dies wird Ihnen helfen, den Weg in dieses Gebiet zu ebnen.Die von Maxim zur Verfügung gestellten Werkzeuge arbeiten mit PyTorch und TensorFlow, die nur auf NVIDIA-GPUs volle Unterstützung für CUDA bieten. Wenn Sie mutig sind, sollten Sie sich auch ROCm von AMD ansehen. Dies ist eine modifizierte Version von PyTorch, welche Beschleunigung auf bestimmten AMD-GPUs erlaubt. Experimentell und offiziell nicht unterstützt sind auch einige der in den AMD-CPUs selbst integrierten Teile.
MAX78000: Was kommt als nächstes?
Da Sie jetzt neue CNNs für den MAX78000 trainieren können, geht es jetzt um den embedded Bereich. Für die Entwicklung werden die von Maxim bereitgestellten Tools genutzt. Die Eclipse-basierte IDE kann von der Website von Maxim heruntergeladen werden. Für meine Entwicklung haben diese Tools auch innerhalb einer virtuellen Maschine gut funktioniert. Wenn etwas Unerwartetes passiert oder Sie Ihren Entwicklungs-PC wechseln müssen, müssen Sie nur ein paar Dateien der virtuellen Maschine verschieben. Als zusätzlichen Bonus können Sie bei Bedarf auch einige Snap Shots Ihrer Entwicklungsumgebung machen. Die Entwicklung der Kaffeemaschine wird vorerst in einfachem C erfolgen. In der Zwischenzeit können Sie bereits einen Blick in die Dokumentation und das Benutzerhandbuch für den MAX78000 werfen. Seien Sie sich bewusst, dass die Dokumentation noch in Arbeit ist. Wenn Sie also das Gefühl haben, dass etwas fehlt, können Sie eine Notiz als GitHub Issue oder unter www.elektormagazine.de/labs/MAX78000 hinterlassen.Haben Sie Fragen oder Kommentare?
Haben Sie technische Fragen oder Kommentare zu diesem Artikel? Dann schicken Sie dem Autor eine E-Mail an mathias.claussen@elektor.com oder kontaktieren Sie Elektor unter redaktion@elektor.comSind Sie bereit, innovative Lösungen für künstliche Intelligenz (KI) zu entwickeln?
Dann setzen Sie den Ultra-Low-Power-Mikrocontroller MAX78000 von Maxim in einer aufregenden neuen Anwendung ein und nehmen am MAX78000-AI-Design-Wettbewerb (powered by Elektor) teil.

Diskussion (0 Kommentare)