
Die Neuronen in neuronalen Netzen verstehen Teil 3: Praktische Neuronen
über

Bisher haben wir in dieser Artikelserie ein neuronales Netz erstellt und ein Verständnis für seine Funktionsweise entwickelt. Wir konnten ihm sogar beibringen, wie die XOR-Funktion funktioniert, wofür die Klassifizierung von Eingabemustern erforderlich ist. In diesem Artikel wollen wir versuchen, einen Teil eines autonomen Fahrsystems zu implementieren: die Erkennung des Zustands von Ampeln.
Es gab schon viele Vorhersagen über selbstfahrende Autos [1], von denen sich keine bewahrheitet hat. Die Schwierigkeit besteht vor allem darin, die Absichten anderer Verkehrsteilnehmer und Fußgänger zu verstehen. Ein großer Teil des autonomen Fahrsystems besteht jedoch darin, alles zu klassifizieren, was die vielen Sensoren und Kameras um das Fahrzeug herum „sehen“. Das reicht von Ampeln und Verkehrsschildern über Straßen- oder Fahrbahnmarkierungen bis hin zu Fahrzeugtypen und Personen. Da wir nun ein funktionierendes neuronales Netz in Form unseres mehrschichtigen Perzeptrons haben, werden wir es verwenden, um die Farben einer Ampel zu erkennen.
Eine der großartigen Eigenschaften der bisher verwendeten Processing-Umgebung ist der einfache Zugriff auf Webcams. Die hier verwendeten Beispiele laufen auf so gut wie jedem Laptop oder PC unter Windows, Linux oder macOS mit einer integrierten oder externen Kamera.
Finden Sie die Kamera!
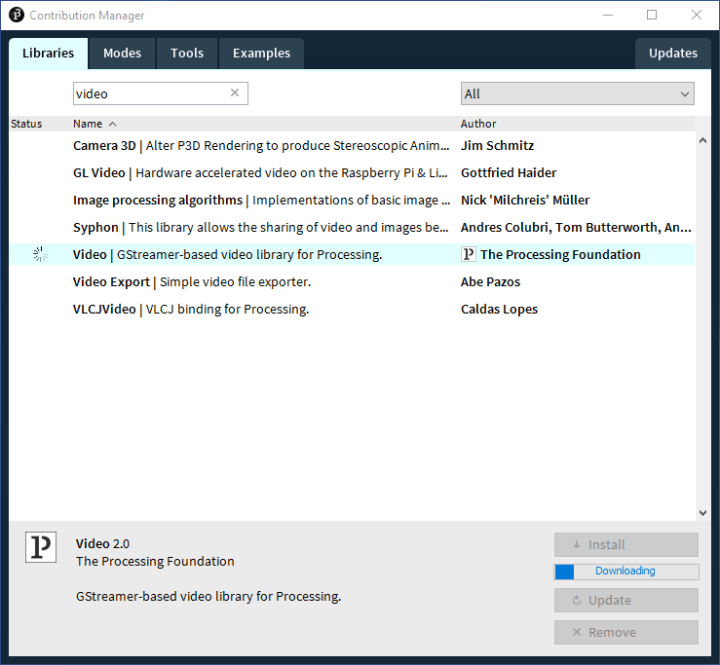
Bevor wir loslegen können, muss eine neue Bibliothek zu Processing hinzugefügt werden, die Zugriff auf alle angeschlossenen Webcams bietet. Wählen Sie im Menü Sketch -> Import Library ... -> Add Library ... (Bild 1), im sich öffnenden Fenster (Bild 2) den Tab Libraries und geben Sie Video in das Suchfeld ein. In der daraufhin angezeigten Liste wählen Sie Video | GStreamer-based video library for Processing aus und klicken dann auf Install. Wie zuvor werden wir den Code aus dem GitHub-Repository verwenden, der für diese Artikelserie vorbereitet wurde [2].
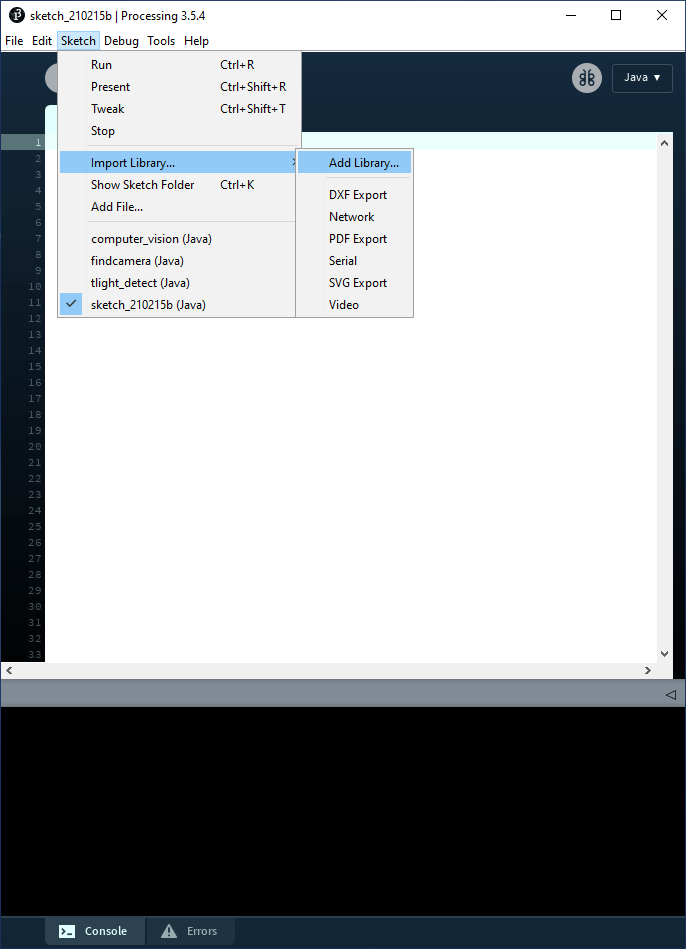
Sobald die Bibliothek installiert ist, können wir das Projekt /trafficlight/findcamera/findcamera.pde ausführen. Dieser Code fragt einfach die Liste der verfügbaren Kameras ab, die an den Computer angeschlossen sind, und ermöglicht dem Benutzer die Auswahl einer Kamera durch Eingabe einer Zahl zwischen 0 und 9. Stellen Sie sicher, dass sich der Fokus an der richtigen Stelle im kleinen findcamera-Fenster befindet (klicken Sie dazu in das Fenster), bevor Sie eine Zahl drücken. Wenn in der Processing-IDE der Fokus gesetzt ist, geben Sie einfach irgendwo im Quellcode eine Zahl ein.
Sobald eine Kameraquelle ausgewählt wurde, wird ihr Bild in einer niedrigen Auflösung von 320 × 240 Pixeln im Fenster angezeigt (Bild 3). In der Textkonsole finden Sie auch den Quellcode, den Sie für die Auswahl Ihrer Kamera für die nächsten beiden Projekte benötigen (Bild 4).

Schließlich brauchen wir noch eine Ampel. Da Sie wahrscheinlich keine zur Hand haben, wurde eine in trafficlight/resources in verschiedenen Dateiformaten angelegt. Drucken Sie einfach eine aus und halten Sie sie griffbereit.
Wenn Sie die Verarbeitung von Projekten stoppen, die die Kamera verwenden, wird möglicherweise die Meldung „WARNING: no real random source present!“ angezeigt. Dies scheint ein Fehler zu sein, der mit der Verwendung der Video-Bibliothek zusammenhängt, aber keinen Einfluss auf die Funktionalität des Codes hat.
Wie sehen Kameras?
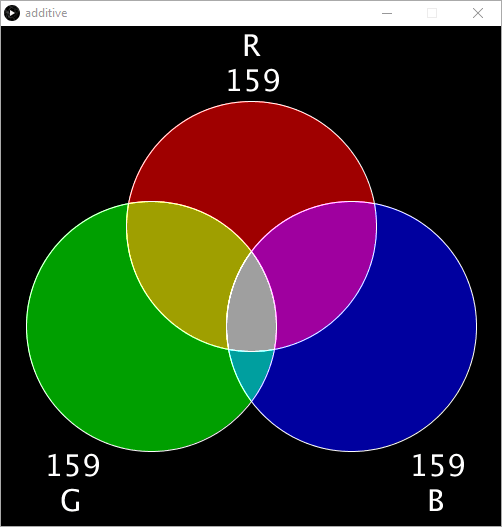
Einer der vielleicht wichtigsten Aspekte bei der Verwendung neuronaler Netze ist es, ein Verständnis dafür zu entwickeln, wie ein Computer die eingehenden Daten interpretieren kann. Im Falle der Kameraeingabe wird das Computerbild durch Mischen der drei Grundfarben Rot, Grün und Blau angezeigt. Dies wird gemeinhin als RGB-Format bezeichnet. Die drei Werte variieren zwischen 0 und 255 (oder 0x00 und 0xFF im Hexadezimalformat). Wenn wir die Kamera auf etwas Blaues richten, würden wir erwarten, dass der B-Wert relativ hoch und die anderen Werte ziemlich niedrig sind. Richten Sie es auf etwas Gelbes, dann sollte es einen hohen R- und G-Wert haben, da Rot und Grün zusammen Gelb ergeben. Zum besseren Verständnis der additiven Farbmischung dürfte das Projekt /trafficlights/addititive/additive.pde hilfreich sein (Bild 5).
Mit diesem Wissen könnte es sinnvoll sein, zu ermitteln, wie unsere Kamera die Farben unserer Ampel „sieht“ und die von ihr gemeldeten RGB-Werte zu notieren. Dann können wir unserem neuronalen Netz die drei Ampelfarben beibringen, so dass es sie als rot, gelb und grün klassifizieren kann.
Festlegung der RGB-Werte
Das Projekt trafficlight/computer_vision/computer_vision.pde ist das nächste Projekt, das wir benötigen. Es zeigt neben dem Bild der ausgewählten Kamera die RGB-Werte an. Mit diesem Projekt können wir also die RGB-Werte aufzeichnen, die die Kamera sieht. Bevor Sie mit dem Code beginnen, vergessen Sie nicht, die Codezeile, die Sie in findcamera.pde festgelegt haben, in Zeile 22 dieses Projekts einzufügen. Dies stellt sicher, dass die von Ihnen gewählte Kamera verwendet wird.
Während Sie die Kamera auf die rote Ampel richten (halten Sie die „Ampel“ ungefähr innerhalb des gestrichelten Kreises), notieren Sie die gesehene Farbe (oben) und die RGB-Werte, die sie definieren (Bild 6). Die RGB-Werte beziehen sich auf den Durchschnitt aller Pixel, die die Kamera im roten Begrenzungsquadrat im Zentrum erfasst. Obwohl es sich um einen Durchschnittswert handelt, ändern sich die RGB-Werte schnell nach oben und unten. Zur Erfassung eines einzelnen Wertes drücken Sie „p“ auf Ihrer Tastatur, und der Code hält bei einem einzelnen Satz von Werten an. Klicken Sie in dieses Fenster, bevor Sie die Taste „p“ drücken, um dem Code den Fokus mitzuteilen. Durch Drücken von „s“ werden die Kameraerfassung und die RGB-Generierung erneut gestartet.

Der hier verwendete Ausdruck der Ampel wurde laminiert, so dass es an einigen Stellen zu Lichtreflexionen kommt. Wenn Sie Ihr Ampelbild mit einem Laserdrucker ausgedruckt haben, kann es ebenfalls passieren, dass Sie eine leicht reflektierende Oberfläche erhalten. Dann kann, obwohl die Kamera auf die rote Ampel gerichtet ist, die „gesehene“ rosa oder sogar fast weiß sein. Das ist für das neuronale Netz natürlich nicht sehr nützlich. Es muss die rote Ampel unter optimalen Bedingungen kennen. Bewegen Sie also die Kamera oder ändern Sie die Beleuchtung, bis Sie das Gefühl haben, einen RGB-Wert erreicht zu haben, der die Farbe optimal darstellt.
Dies wirft auch ein weiteres Problem hinsichtlich der Genauigkeit auf. Autofahrer wissen, wie schwierig es ist, die aktive Ampel zu erkennen, wenn die Sonne in die Augen oder direkt in die Lampen scheint. Wenn wir Menschen nicht unterscheiden können, welche Lampe leuchtet, wie kann es dann ein neuronales Netz herausfinden? Die Antwort lautet: Es kann es nicht. Wenn wir einen robusteren Algorithmus brauchen, müssen wir ihn mit Daten über „schlechte Sicht“ trainieren. Möglicherweise müssen wir auch einen anderen Input bereitstellen, zum Beispiel, woher die Sonne scheint, damit das neuronale Netz weiß, wann „schlechte Sicht“ herrscht und dass es den Datensatz für „schlechte Sicht“ verwenden sollte. Eine andere Idee wäre es, die von der Kamera eingehenden Daten zu verbessern, indem wir vielleicht ein Infrarotbild der Ampel (welche Lampe ist heiß?) oder eine andere clevere Filterung hinzufügen. Aber nicht verzweifeln! Wir werden unseren Trainingsdaten eine gewisse Robustheit verleihen, um mit einer gewissen Variation in der Farbe unserer Ampel fertig zu werden.
Die entscheidende Aufgabe aber ist die Erfassung der RGB-Daten für die rote, gelbe und grüne Lampe der Ampel, so wie Sie sie mit Ihrer Kamera und Ihren Lichtverhältnissen ermitteln. Die Daten, die mit dem Aufbau des Autors gesammelt wurden, sind in Tabelle 1 dargestellt.
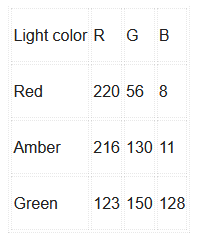
für die drei Ampelfarben.
Erkennung von Verkehrsampeln
Mit diesen Daten können wir nun das neuronale Netz auf die Farben unserer Ampel trainieren. Für diesen letzten Schritt benötigen wir das Projekt trafficlight/tlight_detect/tlight_detect.pde, das in Processing geöffnet ist. Stellen Sie zunächst sicher, dass der korrekte Initialisierungscode für die Kamera in Zeile 38 (aus find_camera.pde) eingefügt wird.
Dieses Projekt verwendet einen MLP-Knoten mit drei Eingängen, sechs verborgenen und vier Ausgängen (3/6/4). Die drei Eingänge stehen für die drei Farben R, G und B. Drei der vier Ausgänge dienen der Klassifizierung von „Rot“, „Gelb“ und „Grün“ der Ampel. Der vierte wird später verwendet. Die willkürlich gewählten sechs versteckten Knoten sollte ausreichen, um die Klassifizierungsaufgabe zu bewältigen. Wir werden feststellen, dass diese Konfiguration funktioniert, und wie zuvor werden Sie ermutigt, mit weniger oder mehr versteckten Knoten zu experimentieren.
Wenn Sie den Code so ausführen, wie er ist, arbeitet das neuronale Netz ohne jeglichen Lernprozess. Die Ergebnisse (Bild 7) zeigen, dass jede Farbe als alle gültige Farbe klassifiziert wird, die das Netzwerk erkennen soll.

Das Anlernen des neuronalen Netzes erfolgt in und um Zeile 51. Entfernen Sie die Kommentierung der ersten drei Methoden und fügen Sie die RGB-Werte hinzu, die Sie zuvor ermittelt haben. Die drei Methoden, die zur Definition von Rot, Gelb und Grün verwendet werden, sind folgende:
teachRed(159, 65, 37)
teachAmber(213, 141, 40)
teachGreen(128, 152, 130)
Jedes Mal, wenn diese Funktionen aufgerufen werden, wird das Netz darauf trainiert, diese RGB-Kombination als die zugehörige Farbe zu klassifizieren (Bild 8). Um Beleuchtungsschwankungen und automatische Änderungen der Belichtungseinstellungen durch die Kamera auszugleichen, werden die RGB-Werte mit Hilfe der Funktion
randomise()(Zeile 336) ein wenig variiert (±4). Auch hier können Sie mit der Wirksamkeit dieses Ansatzes und dem Grad der Zufallssteuerung experimentieren.
Das Training des Netzes geht im Vergleich zu früheren Projekten sehr schnell, da wir die Fehlerwerte beim Lernen nicht mehr in eine Datei schreiben. Führen Sie das Projekt einfach aus, und nach ein paar Sekunden beginnt das neuronale Netz, die Farbe im roten Begrenzungsquadrat des Kamerafensters zu bewerten (Bild 9).

Die im Blickfeld der Kamera befindliche Ampel wird ab Zeile 156 ermittelt. Die erfassten RGB-Farben werden auf die Eingänge des MLPs angewendet, und die Ausgabe des Netzes wird berechnet:
network.setInputNode(0, (float) r / 255.0);
network.setInputNode(1, (float) g / 255.0);
network.setInputNode(2, (float) b / 255.0);
network.calculateOutput();
Die Entscheidung über die gesehene Farbe wird dann ab Zeile 171 getroffen. Die Ausgabe der einzelnen Ausgangsknoten wird ausgewertet. Liegt die Klassifizierungssicherheit über 90 % (0,90), wird die gesehene Farbe in einem Kreis zusammen mit dem Klassifikator „Rot“, „Gelb“ oder „Grün“ angezeigt.
// If likelihood of ‘Red’ > 90%...
if (network.getOutputNode(0) > 0.90) {
fill(200, 200, 200);
// …write “Red”…
text("Red", 640+(100), 320);
// … and set color to the color seen.
fill(r, g, b);
} else {
// Otherwise, set color to black
fill(0, 0, 0);
}
// Now draw the color seen in a circle
ellipse(640+(50), 300, 40, 40);
Sie können mit der Präzision des MLPs experimentieren, indem Sie die Kamera in verschiedenen Winkeln und unter verschiedenen Lichtverhältnissen auf die verschiedenen Ampeln richten. Versuchen Sie auch, die Kamera auf Objekte in Ihrer Umgebung zu richten, die Ihrer Meinung nach den Farben, die das MLP gelernt hat, nahe kommen.
Sie werden feststellen, dass eine Vielzahl von Farben als eine bekannte Farbe falsch klassifiziert wird. Im Beispiel des Autors wird die Klassifizierung „grün“ auch für die Ampelumrandung, den Rahmen und den gesamten Bildhintergrund angegeben (Bild 10).

Schärfung der Klassifizierung durch das neuronale Netzwerk
Aus den angezeigten RGB-Werten wird ersichtlich, dass die an das MLP übergebenen Farben der gewünschten Klassifizierung für „Grün“ recht nahe kommen. Es gibt mehrere Möglichkeiten, die Klassifizierung zu verbessern. Die erste wäre, die 90%-Marke für eine genaue Klassifizierung auf einen höheren Wert anzuheben. Eine andere Möglichkeit wäre, die Anzahl der Lernphasen (Epochen) zu erhöhen. Eine weitere besteht darin, die Implementierung der Klassifizierung zu überdenken.
Bislang haben wir uns darauf konzentriert, was wir positiv klassifizieren möchten. Manchmal kann es jedoch hilfreich sein, dem neuronalen Netz beizubringen, was nicht zu den Mustern gehört, nach denen wir suchen. Im Grunde können wir sagen: „Das sind drei Dinge, nach denen wir suchen, aber hier sind einige ähnliche Dinge, nach denen wir definitiv nicht suchen.“ An dieser Stelle kommt unser vierter Ausgabeknoten ins Spiel. Um noch einmal zum Projekt computer_vision.pde zurückzukehren, können wir die RGB-Werte für Farben erfassen, die wir als „andere“ klassifizieren möchten. Als Beispiel wurden die RGB-Werte für die dunkle Ampelumrandung, den weißen Rand und den blauen Hintergrund erfasst, wobei die Ergebnisse in Tabelle 2 dargestellt sind.

Zurück in tlight_detect.pde, können diese Werte mit der Methode teachOther() als „Andere“ unerwünschte Farben eingelernt werden. Entfernen Sie einfach das Kommentarzeichen in Zeile 60 und fügen Sie Ihre RGB-Werte ein:
teachOther(76, 72, 35);
teachOther(175, 167, 138);
teachOther(152, 167, 161);
Eine erneute Ausführung des Projekts führt zu einer deutlichen Verbesserung. Der Bereich um die Ampel (Umrandung, Rahmen, Hintergrund) wird als „Other“ anstatt als „Grün“ klassifiziert (Bild 11).

Experimente bis zum nächsten Mal
In diesem Artikel haben wir nun gesehen, wie ein neuronales Netz ein reales Klassifizierungsproblem löst. Wir haben auch gelernt, dass es helfen kann, sowohl die gewünschten als auch die unerwünschten Klassifizierungsdaten zu lernen.
Warum versuchen Sie nicht, auf diesem Beispiel aufzubauen und Folgendes zu untersuchen?
- Wie „robust“ kann man das MLP gegen Kamerawinkel und Belichtungsänderungen machen? Ist es besser, die Lerndaten stärker zu randomisieren oder die Messlatte für die Klassifizierung höher zu legen (>90%)?
- Verbessert sich die Genauigkeit, wenn man die Anzahl der Other-Ausgabeknoten erhöht und jedem eine unerwünschte Farbe beibringt?
- Welche Auswirkungen hat die Verringerung oder Erhöhung der Anzahl der versteckten Knoten auf das System?
- Würde ein vierter Eingang für „allgemeine Helligkeit“ helfen, die Erkennungsgenauigkeit bei unterschiedlichen Lichtverhältnissen zu erhöhen?
Während es großartig ist, neuronale Netze auf leistungsstarken Laptops und PCs auszuführen, wünschen sich viele von uns eine solche Fähigkeit auf den kleineren Controllern, die auf Boards wie dem Arduino verwendet werden. In unserem letzten Artikel dieser Reihe werden wir deshalb einen RGB-Sensor und einen Arduino verwenden, um ein neuronales Netzwerk zur Farberkennung zu implementieren. Vielleicht bildet es die Grundlage für Ihr nächstes smartes Arduino-Projekt!
Haben Sie Fragen zu Praktischen Neuronen?
Haben Sie technische Fragen oder Kommentare zu diesem Artikel? Dann schreiben Sie bitte dem Autor eine E-Mail an stuart.cording@elektor.com.
Übersetung: Angela | Textmaster
Diskussion (0 Kommentare)